Expert Network Consolidation: Why the AI Investment Research Stack Lives or Dies on Primary Content
Expert network consolidation is collapsing three procurement decisions into one. The durable differentiator isn't the AI layer, it's the fidelity of the primary content underneath.
Expert Network Consolidation: Why the AI Investment Research Stack Lives or Dies on Primary Content
For the past decade, you've run three separate procurement conversations. One for transcription. One for expert networks.
One, more recently, for LLM tooling. Three vendor relationships, three budgets, three sets of contracts sitting in three different folders on your desktop.
As of July 2024, that structure is collapsing. AlphaSense's roughly $930 million acquisition of Tegus merged the two largest expert-transcript libraries, SEC filings, broker research, earnings transcripts, and an AI search layer into a single platform. The company simultaneously closed a $650 million funding round at a $4 billion valuation.
Independent analysts called it "a seismic moment likely to drive further consolidation in Expert Networks and Data & Analytics." Three RFPs are becoming one.

Here's the part that doesn't show up in the press releases: in a consolidated AI investment research stack, the search layer commoditizes fast. Every platform ships an AI search box. The durable differentiator isn't the model or the interface.
It's the fidelity of the primary content feeding it. And that's the one thing you can't evaluate in a 30-minute demo.
Expert network consolidation changes who owns the relationship, the data, and the surface through which your analysts consume research. It also changes what breaks when the underlying content isn't accurate. A misattributed speaker tag or a garbled financial term doesn't just sit in a transcript anymore.
It propagates through every AI-generated summary, every query response, every downstream workflow that touches that content. The failure mode of a consolidated stack isn't a bad transcript. It's an expensive hallucination with no audit trail back to the source.
This piece analyzes the defining transaction, the pricing mechanics accelerating consolidation, and why transcript quality has quietly become the critical infrastructure underneath the entire stack.
The AlphaSense Tegus Acquisition: Anatomy of Expert Network Consolidation
The deal that redrew the map of primary research infrastructure didn't arrive as a surprise. It arrived as an inevitability. On July 8, 2024, AlphaSense completed its acquisition of Tegus, merging the two largest expert-transcript libraries in the market under a single roof (PR Newswire).
The transaction valued Tegus at roughly $930 million. That figure alone signals how the market prices primary research content in an era where AI consumption is the default mode.
But the deal terms only tell part of the story. What matters more is what the combined entity now controls, what independent observers made of the move, and what it means for every firm operating in the expert network and financial data ecosystem.
Deal Terms and Valuation: $930M Acquisition, $650M Raise, $4B Platform
AlphaSense first announced the Tegus acquisition in June 2024 and closed it weeks later on July 8. Alongside the deal, the company closed a $650 million funding round co-led by Viking Global Investors and BDT & MSD Partners, pushing AlphaSense's valuation to $4 billion (PR Newswire).
Those numbers deserve context. A $930 million price tag for a transcript library tells you that the market doesn't view expert call content as a commodity. It views it as a strategic asset, one valuable enough to anchor a $4 billion platform.
The capital raise wasn't incidental to the acquisition. It was structural. Viking Global and BDT & MSD Partners don't co-lead $650 million rounds for incremental product improvements.
They fund platform bets where the combined entity can own an entire workflow, from content ingestion through AI-powered delivery.
What the Combined Platform Consolidates
Before the deal, a buy-side research team might source SEC filings and broker research from AlphaSense while separately accessing Tegus's expert transcript library. Those were two platforms, two logins, two procurement relationships.
Now they're one. Tegus brought a proprietary content set of more than 100,000 expert call transcripts, coverage spanning 4,000+ public companies across 50+ sectors (AlphaSense). That library merged into AlphaSense's existing platform, which already aggregated SEC filings, broker research, earnings transcripts, and news, all searchable through an AI-powered interface.
The result is a single surface where an analyst can query across document types that previously lived in separate systems. An earnings call transcript sits alongside an expert call transcript alongside a 10-K filing. The AI layer doesn't distinguish between them.
It treats all of it as content to retrieve, summarize, and synthesize.
That's the architectural shift. The unit of research consumption moves from "I need to schedule a call" or "I need to pull a filing" to "I need an answer." The platform that holds the broadest, deepest content library wins the query.
Why Independent Analysts Called It a Seismic Moment
Asymmetrix Intelligence described the transaction as consolidating the two biggest players in the expert-transcript library industry, calling it "a seismic moment likely to drive further consolidation in Expert Networks and Data & Analytics" (Asymmetrix Intelligence).
That framing matters. It's not just a single deal between two companies. It's a structural signal about where the entire sector is heading.
When the two largest transcript libraries merge, every other firm in the ecosystem has to recalculate its position.
For expert networks and financial data platforms, the implications are immediate. The competitive surface isn't just "who has the best experts" or "who has the fastest turnaround." It's who controls the most comprehensive, highest-fidelity content library that an AI layer can query against.
Consolidation compresses the stack, and the firms that thrive in a compressed stack are the ones whose primary content holds up under AI-scale consumption.
This is the context for everything that follows. The pricing models are shifting. The procurement conversations are collapsing.
And the quality of the content feeding these consolidated platforms has never mattered more.
Three Procurement Conversations Collapsing Into One AI Investment Research Stack
Two years ago, a Head of Research at a mid-size buy-side firm managed three distinct vendor relationships. Transcription went through operations. Expert network access sat with the research team.
And LLM tooling? That was a pilot project run by someone in data science or IT, often without a formal procurement process at all.
Those three conversations are merging into one. And the speed of that collapse is reshaping how every expert network and financial data platform thinks about its product, its pricing, and its competitive position.
Transcription: From Back-Office Utility to Primary Content Layer
Transcription used to be invisible. It was a back-office function, procured on price, managed by an ops team, and rarely discussed in the same room where research strategy was set. The transcription vendor was chosen the way you'd choose a janitorial service: lowest bid, acceptable quality, minimal friction.
That framing no longer holds. When transcripts become the content layer that an AI search interface queries against, they stop being operational output and start being product infrastructure. Every entity, every speaker attribution, every financial figure in a transcript is now a retrievable data point.
The shift isn't conceptual. It's architectural. In a consolidated research platform, the transcript isn't delivered to an analyst who reads it and applies judgment.
It's ingested by a model that treats its contents as ground truth. The quality bar for transcription has moved from "good enough for a human to parse" to "accurate enough for a machine to cite."
Expert Networks: From Per-Call Brokerage to Searchable AI-Queryable Content Libraries
The traditional expert network model is built around the call. A client requests access to a domain expert, compliance screens the interaction, the call happens, and the network charges a premium for brokering that connection. The value is in the access.
Consolidation reframes that value. When platforms like the combined AlphaSense-Tegus entity offer more than 100,000 expert call transcripts searchable through an AI interface, the call itself is no longer the terminal unit of value. The transcript is.
And the transcript's value compounds every time it's queried, summarized, or synthesized alongside other content.
This doesn't eliminate the live expert call. It does change its position in the stack. The call becomes a content-generation event whose downstream value depends entirely on how well it's captured, structured, and made retrievable.
Expert networks that have invested heavily in building proprietary transcript libraries understand this intuitively. They've been building for this shift.
LLM Tooling and MCP Connectors: The New Consumption Surface for Primary Research
The third procurement conversation (LLM tooling) barely existed as a formal line item 18 months ago. Now it's the surface through which the other two are consumed.
MCP integrations are a useful example. These connectors pipe expert call transcripts and other primary content directly into Claude and other LLMs, turning the model into the default research interface. An analyst doesn't log into a transcript portal and read.
They ask a question and get an answer grounded in the underlying content.
This changes the buyer's calculus fundamentally. The LLM layer isn't a separate product anymore. It's the consumption surface for the expert network's content library.
And when one vendor controls all three layers (content, access, and AI interface) the buyer's three RFPs collapse into a single vendor evaluation.
What Concentrates When the Buy Consolidates
The Head of Research who used to manage three vendor relationships now manages one. That's operationally simpler. It's also structurally riskier.
A single consolidated platform owns the relationship, the data, and the interface. That concentrates leverage on both sides. The buyer gets a unified workflow.
The vendor gets a stickier contract. But it also creates a single point of failure where the quality of every layer is only as strong as the weakest component in the stack.
Here's what compresses in the consolidation of expert network procurement into a single AI research stack:
- Vendor relationships go from three to one, reducing operational overhead but eliminating the natural quality checks that come from separate procurement processes.
- Quality accountability shifts from distributed (each vendor owns its layer) to concentrated (one vendor owns everything, and the weakest layer drags down the rest).
- Switching costs increase dramatically, because leaving one layer means leaving all three.
The firms navigating this transition most effectively are the ones asking a harder question than "which platform has the best AI features?" They're asking what happens to the entire stack when the content layer underneath it isn't accurate. That's the question the next sections address.
How Expert Network Pricing Models Shift Under Consolidation
The traditional expert network model prices the call. A premium, historically well over $1,000 for an hour of targeted conversation with a domain expert. That pricing reflects real value: sourcing, vetting, compliance screening, and scheduling a person with specific knowledge that a buy-side analyst can't get from a filing or a sell-side note.
But when the same insight is consumed as a query against a transcript library inside an AI workflow, the unit of consumption shifts. It's no longer the call. It's the query.
And that shift puts structural pressure on per-call ARPU across the entire expert network ecosystem.
This isn't a criticism of any firm's pricing strategy. It's a structural observation about what happens when consolidation changes the economic unit that buyers optimize around.
From Per-Call ARPU to Per-Seat and Per-Query Pricing
In the legacy model, expert network economics revolve around call volume. More calls, more revenue. The buyer pays per interaction, and the network's margin scales with the premium it can charge for access to high-quality experts.
Consolidated platforms invert that logic. When a firm-wide subscription gives every analyst access to a searchable library of 100,000+ expert call transcripts, the buyer stops thinking in terms of individual calls and starts thinking in terms of seats and usage. The procurement conversation moves from "how many calls will we schedule this quarter?"
to "how many analysts need access to the platform?"
That's a fundamentally different economic relationship. Per-call pricing rewards scarcity and exclusivity. Per-seat pricing rewards breadth of content and depth of coverage.
The firms thriving in this transition are the ones whose content libraries are comprehensive enough to justify the subscription, and whose transcripts are structured well enough to surface useful answers through an AI interface.
Tegus's At-Cost Call Pricing as a Consolidation Signal
Tegus's pricing model anticipated this shift before the AlphaSense acquisition made it explicit. According to Sacra, Tegus charges expert calls at cost, avoiding the per-call markup typical of traditional expert networks. Revenue is driven by seat-based, firm-wide subscription expansion rather than per-call fees.
That model is itself a consolidation signal. When a platform prices calls at cost, it's telling the market that the call isn't the product. The transcript library is.
The call is a content-generation event whose value accrues to the platform's searchable archive, not to the individual interaction.
It's worth understanding what this does to competitive dynamics. A firm competing on per-call premiums faces a structural disadvantage against a platform that bundles calls into a subscription and monetizes the resulting content library at scale. The economics favor the platform with the largest, most queryable archive.
Why Firm-Wide Subscriptions Compress Standalone Expert Network Economics
A single firm-wide subscription replaces what used to be a stack of per-call and per-seat line items spread across multiple vendors. For the buyer, that's simpler budgeting and lower total procurement friction. For the vendor ecosystem, it concentrates spend.
The compression is real. When one platform captures the transcription budget, the expert network budget, and the AI tooling budget in a single contract, standalone providers in each category face a narrower addressable market. The buyer who previously ran three RFPs now runs one.
But here's what makes this pricing shift relevant to content quality. When per-call revenue compresses, the value of the reusable content asset (the transcript library) increases relative to the one-time call. Each transcript isn't just a record of a conversation anymore.
It's an appreciating asset that gets queried hundreds or thousands of times across the platform's user base.
That changes the calculus on transcript fidelity entirely.
A transcript with garbled financial figures or misattributed speakers doesn't just fail the analyst who commissioned the original call. It fails every subsequent query that retrieves it. The cost of a transcription error multiplies with every retrieval event.
In a per-call model, a bad transcript disappoints one client. In a subscription model built on a searchable archive, a bad transcript degrades the platform's core product for every user who encounters it.
The firms navigating expert network pricing model transitions understand this intuitively. The smartest ones are treating transcript quality not as a cost center to minimize, but as the infrastructure that justifies the subscription price their clients pay. When the economic unit shifts from the call to the content library, the fidelity of that library becomes the thing the entire business model depends on.
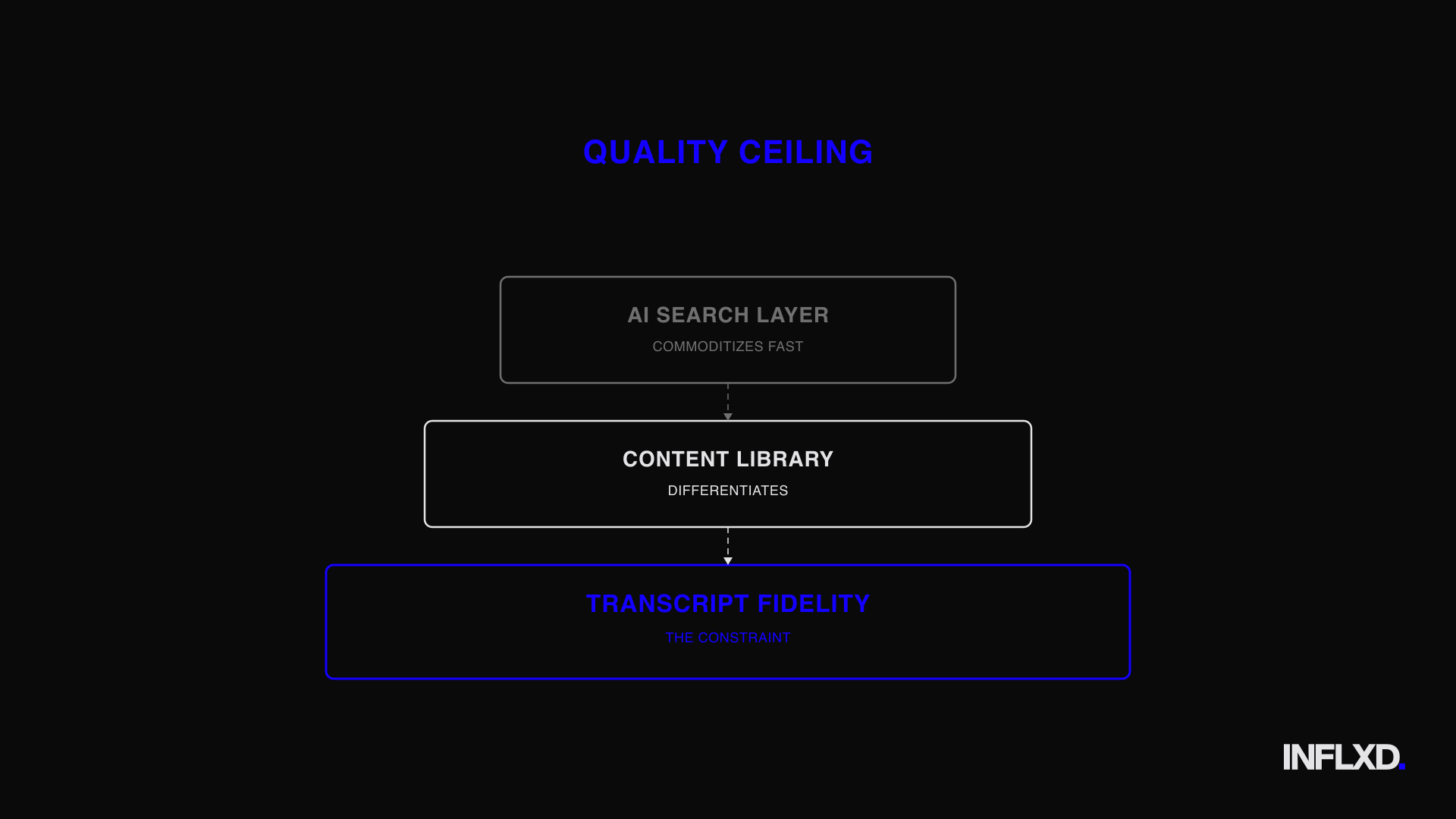
Why the AI Search Layer Commoditizes and Primary Content Quality Becomes the Differentiator
Every consolidated platform in the market ships an AI search box. It's the first thing you see in the demo. It's the centerpiece of the sales deck.
And it's the least defensible component in the entire stack.
Foundation models improve on a schedule no single platform controls. OpenAI, Anthropic, Google, and a growing roster of open-source projects push capability forward on quarterly (sometimes monthly) cycles. A retrieval-augmented search interface built on GPT-4 today will be built on something meaningfully better in 18 months.
The platform didn't create that improvement. It inherited it.
This is the structural reality of the AI layer in a consolidated research stack: it commoditizes fast. The search box is table stakes. The differentiator sits underneath it.
Every Consolidated Platform Ships an AI Search Box. That's Not the Moat.
When the unit of research consumption shifts from the call to the query, the AI interface becomes the product surface. But that surface is only as valuable as what it retrieves. Two platforms running identical foundation models, identical retrieval architectures, and identical prompt engineering will produce entirely different outputs if the content they're grounded in diverges in quality.
This is where the consolidation of expert networks into AI-powered research platforms creates a counterintuitive dynamic. The more sophisticated the AI layer becomes, the more it exposes weaknesses in the content layer. A better model doesn't compensate for a noisy transcript.
It amplifies the noise with greater confidence.
Consider what happens structurally. If entity recognition in the underlying transcript is wrong (a ticker misidentified, a drug name garbled, a company name rendered as a phonetic approximation), the AI search layer retrieves that error and presents it as fact. If speaker diarization is off, the AI misattributes a critical statement to the wrong expert.
If financial figures are transcribed incorrectly, the AI confidently cites numbers that don't match reality.
The model doesn't know the content is wrong. It can't. It treats the transcript as ground truth because that's what retrieval-augmented generation does.
The quality ceiling of the entire platform is set by the accuracy of the primary content, not the sophistication of the model querying it.
Transcript Fidelity: The Part of the Stack a Buyer Can't Evaluate in a Demo
Here's the problem for any firm evaluating a consolidated research platform: demos are optimized. The content is curated. The queries are pre-selected.
The transcripts powering the demonstration have been reviewed, cleaned, and chosen specifically because they produce impressive results.
That's not a criticism of any platform's sales process. It's how enterprise software demos work. But it creates a dangerous gap between what a buyer sees and what the platform delivers at scale.
The real test isn't what happens when the AI encounters a clean transcript of a native English speaker discussing a well-covered large-cap company. The real test is what happens when the source audio features a heavy accent, overlapping speakers, or domain-specific terminology that generic ASR models weren't tuned for. Biotech nomenclature.
Emerging-market company names. Niche industrial processes described in shorthand by a 30-year veteran who doesn't slow down for the microphone.
Generic transcription vendors, the commodity ASR providers that have historically served as the capture layer for expert call audio, weren't built for this. Their models optimize for general accuracy across broad use cases. They don't carry domain-tuned vocabularies for pharmaceutical compounds, financial instruments, or the specialized terminology that makes expert calls valuable in the first place.
That gap between general-purpose transcription and domain-specific accuracy is invisible in a demo. It's only visible at scale, when analysts start encountering AI-generated answers grounded in transcripts that got the details wrong.
The Structural Argument: Content Quality Is the Constraint, Not the AI
This is INFLXD's analytical read on where consolidation creates durable advantage. In a single-vendor world where the AI layer, the content library, and the expert access all sit under one roof, the constraint on platform value isn't the model. It's the fidelity of the primary content the model is grounded in.
The AI layer will keep getting better. That's a given. But the content layer doesn't improve automatically.
It improves only when the transcription infrastructure underneath it is purpose-built for the domain: accurate entity recognition, reliable speaker attribution, correct financial figures, and structured output that an AI retrieval system can trust.
The firms that recognize this are treating transcript quality as the foundation of their consolidated platform strategy. Not as a line item to minimize. Not as a back-office function to outsource to the lowest bidder.
As the infrastructure that determines whether their AI surface delivers accurate answers or confident errors.
In a consolidating market, the platform with the best AI and the worst transcripts loses to the platform with good-enough AI and pristine content. The model is replaceable. The content is not.
Where Transcription Errors Compound in a Consolidated AI Research Platform
The previous sections established that the AI layer commoditizes and the content layer differentiates. But that framing is still abstract. To understand why transcript fidelity is structural, you need to trace how specific categories of transcription error propagate through a consolidated stack.
Each failure mode is distinct. And each one compounds differently when the transcript is consumed via AI query rather than read directly by a human analyst.
This isn't about any single platform's shortcomings. It's a structural consequence of consolidation itself: the more layers of AI abstraction that sit between raw audio and the analyst, the more critical the initial capture becomes.
Entity Recognition Failures: Tickers, Drug Names, and Financial Figures
Generic ASR models are trained on conversational English. They're optimized for breadth, not for the specialized vocabulary of pharmaceutical development, energy trading, or semiconductor supply chains. When an expert discusses EBITDA margin compression in mid-cap specialty chemicals, a generic model may mangle the domain-specific terms that carry the actual analytical value.
The failures are predictable. Ticker symbols get rendered as common words. Drug compound names (often long, phonetically complex, and absent from general-purpose dictionaries) come through garbled.
Financial figures lose decimal places or swap units entirely.
In a standalone transcript, an analyst catches these. They know the company, they know the context, and they can cross-reference with the audio. In a consolidated platform where the transcript is retrieved by an AI model in response to a query, there's no human in the loop at the point of retrieval.
The model treats the garbled entity as ground truth and serves it to the analyst with full confidence.
The transcription vendors historically serving expert call audio weren't built for this level of domain precision. Their models lack the specialized vocabularies that expert network content demands. That gap didn't matter much when a human always sat between the transcript and the decision.
It matters enormously when a RAG pipeline does.
Speaker Diarization Errors and Misattributed Intelligence
Speaker diarization (identifying who said what in a multi-speaker recording) is a second, distinct failure mode. It's also the most dangerous one in a consolidated stack.
When the AI misidentifies the speaker, every downstream output carries the misattribution. A summary attributes a bearish outlook on inventory levels to the former VP of Supply Chain when it was actually the interviewer paraphrasing a sell-side note. A search result surfaces a quote tagged to an industry expert that was actually a clarifying question from the moderator.
The analyst consuming that output has no reason to doubt the attribution. They didn't listen to the call. They queried the platform, got an answer, and built it into their thesis.
The misattribution is invisible at the point of consumption.
This is particularly acute in expert calls, where two speakers often have similar audio profiles (both on the same video call, both using similar microphones, both speaking the same language in similar registers). Generic diarization models struggle with these conditions. Domain-aware transcription infrastructure handles it differently, using contextual cues and structured speaker identification to maintain attribution accuracy even in acoustically similar environments.
How Upstream Transcript Errors Propagate Through AI Summarization and RAG Pipelines
The compounding effect is what makes this a consolidation problem rather than just a transcription problem.
In a pre-consolidation workflow, a transcript error had a limited blast radius. One analyst read one transcript, noticed something off, pulled up the audio, and corrected their notes. The error was containable because a human was always the final consumer.
In a consolidated AI research platform, the transcript feeds a retrieval-augmented generation pipeline. That pipeline serves every analyst on the platform who asks a related question. A single entity recognition failure or diarization error doesn't affect one person.
It affects every query that touches that transcript, across every user, for as long as the content sits in the library.
Three failure points compound silently in this architecture. First, real-time capture introduces errors at the point of transcription. Second, post-call processing (if it exists) may fail to catch domain-specific mistakes that a general QA pass wouldn't flag.
Third, downstream integration into the AI layer propagates whatever errors survived the first two stages into every retrieval event.

The analyst reviewing the final AI output may be working with data significantly degraded from the original conversation. And they have no visibility into where that degradation occurred. There's no red flag, no confidence score, no annotation indicating that the underlying transcript had a 12% word error rate on financial terminology.
The AI presents its answer cleanly.
This is why the smartest firms in the expert network and financial data ecosystem are re-evaluating their transcription vendor infrastructure as they consolidate. The transcription layer isn't a back-office cost to minimize. It's the first link in a chain where every subsequent link inherits whatever errors the first one introduced.
In a consolidated stack, the cost of a transcription error isn't a bad transcript. It's a degraded platform.
Evaluating Primary Research Platform Consolidation: What to Ask Before the Single-Vendor Buy
Whether you're consolidating onto a single platform or being consolidated into one, the evaluation framework matters. Most of the attention in these procurement cycles goes to the AI features: the search interface, the summarization quality, the speed of the query response. That's understandable.
It's what the demo showcases.
But the previous sections have made the structural case that the AI layer commoditizes and the content layer differentiates. If that's true, then the content layer deserves evaluation rigor at least equal to what you're applying to the model sitting on top of it. Here's what that evaluation looks like in practice.
Due Diligence Questions for Transcript Accuracy and Entity-Level Fidelity
The first question is deceptively simple: what entity-level accuracy do the underlying transcripts actually achieve? Not on benchmark audio. Not on a curated demo set.
On real-world expert calls with accented speakers, cross-talk, and dense domain jargon.
Most transcription vendors can quote a word error rate. Fewer can quote an entity-level accuracy rate, meaning the percentage of tickers, company names, drug compounds, and financial figures rendered correctly. Those are different metrics, and the second one matters far more for AI retrieval.
The follow-up questions sharpen the picture:
- How is accuracy measured? Is there a systematic audit process, or is the quoted figure derived from a one-time benchmark on favorable audio?
- What's the domain model coverage? Does the transcription infrastructure carry specialized vocabularies for financial instruments, pharmaceutical nomenclature, and sector-specific terminology? Or is it general-purpose ASR with a financial glossary bolted on?
- How are accuracy figures validated? Is there an independent measurement methodology, or are you relying on the vendor's self-reported numbers?
These aren't gotcha questions. They're the same due diligence you'd apply to any data vendor whose output feeds your investment process. The difference is that in a consolidated stack, this vendor's output feeds everything.
How to Stress-Test the Content Layer Beyond the Demo Environment
Demos are optimized. That's not a criticism. It's a structural feature of enterprise software sales.
The transcripts powering a demo have been selected because they produce clean, impressive AI outputs. The real question is what happens outside that curated environment.
Stress-testing the content layer means requesting sample outputs on difficult audio. Ask for transcripts of calls featuring non-native English speakers discussing niche subsectors. Ask for multi-speaker calls where participants talk over each other.
Ask for calls heavy with acronyms and proprietary terminology that wouldn't appear in a general-purpose language model's training data.
Then evaluate the speaker diarization methodology specifically. Is it automated-only, or does a human review layer verify speaker attribution? In expert calls with two or three speakers, diarization errors are where the highest-stakes misattributions occur.
An automated-only pipeline may perform well on clean two-party audio and fail on the messy, real-world conditions that characterize actual expert conversations.
The point isn't to find a platform that never makes errors. It's to find one whose error rate on difficult, domain-heavy content is meaningfully lower than what commodity transcription vendors deliver. That gap is the gap that determines whether the consolidated platform's AI outputs are trustworthy or merely fluent.
Structured Output and Metadata: The Hidden Requirements for AI-Ready Transcripts
There's a third dimension that most evaluations miss entirely. It's not about whether the words are right. It's about whether the transcript is structured for AI consumption.
A transcript that's accurate but unstructured is searchable. A transcript that's accurate and structured is queryable. The difference matters enormously in a consolidated stack where the retrieval pipeline needs to locate specific passages, identify speakers, and segment content by topic.
The specific capabilities to evaluate:
- Word-level timestamps that allow the AI to cite precise moments in the source audio, enabling verification workflows.
- Topic segmentation that breaks the conversation into thematic blocks, so retrieval can surface the relevant passage rather than the entire transcript.
- Entity tagging that marks tickers, company names, people, and financial figures as structured metadata rather than raw text.
- Speaker attribution metadata tied to each utterance, not just a speaker label at the top of the document.
Without these features, the RAG pipeline is working with unstructured text and guessing at structure. It can still produce answers. But it can't produce answers with the precision, traceability, and citation specificity that buy-side workflows demand.
These aren't nice-to-haves. They're the features that determine whether a transcript functions as a data asset or just a text file. In a single-vendor stack, the content layer is the foundation everything else stands on.
Evaluating it with anything less than full rigor means accepting a risk that compounds through every layer above it.
Transcript Quality as Critical Infrastructure in Expert Network Consolidation
The previous sections traced a clear structural arc. Three procurement conversations are collapsing into one. Pricing models are shifting from per-call premiums to subscription-based content libraries.
The AI search layer commoditizes while the content layer differentiates. And transcription errors compound through every downstream retrieval event in a consolidated stack.
That arc leads to a single conclusion: in a consolidating market, the durable advantage accrues to whoever controls the highest-fidelity primary content. Not the best model. Not the slickest interface.
The cleanest, most structured, most reliable content feeding the entire platform.
The constraint isn't the AI layer. It never was. It's the commodity transcription tooling that historically captured the underlying audio.
Why Domain-Tuned Transcription Is Infrastructure, Not a Feature
There's a meaningful difference between treating transcription as a feature checkbox and treating it as infrastructure. A feature is something you ship and move on from. Infrastructure is something the entire system depends on, something whose failure cascades through every layer above it.
Expert networks and financial data platforms consolidating their stacks are sophisticated organizations. The smartest of them already recognize that the transcription layer isn't a procurement afterthought. It's the foundation for the whole consolidated platform: domain-tuned capture, accurate entities and figures, reliable diarization, and structured, verifiable output.
Generic ASR providers weren't built for this. Their models optimize for broad conversational accuracy, not for the specialized vocabulary of expert calls covering pharmaceutical pipelines, semiconductor supply chains, or energy derivatives. That's not a failure of the expert networks commissioning the transcription.
It's a failure of the transcription vendor ecosystem to build domain models that match the precision these firms and their clients require.
Domain-tuned transcription infrastructure solves a different problem than general-purpose ASR. It carries finance-native vocabularies. It handles entity recognition for tickers, drug compounds, and financial instruments as a core capability rather than an afterthought.
It pairs automated capture with human-in-the-loop QA processes that catch the errors a general model can't even identify as errors.
That's infrastructure. And in a single-vendor stack where every AI output traces back to a transcript, it's the infrastructure that determines platform integrity.
The Role of Clean Primary Content in a Single-Vendor AI Stack
This is INFLXD's position, and it's a structural one: we stand with expert networks and financial data platforms as the infrastructure layer that ensures the primary content feeding their consolidated AI stack is clean, structured, and reliable. Domain-tuned ASR, finance-native editorial teams, and a human-in-the-loop QA process aren't features. They're the foundation.
The firm that owns clean primary content and the AI surface on top of it is the one consolidation rewards. A platform valued at $4 billion is only as trustworthy as the transcripts its AI retrieves. Every query, every summary, every AI-generated insight inherits the accuracy (or the errors) of the content layer underneath.
Building a consolidated platform on commodity transcription is building on a foundation you can't inspect from the outside. The demo looks the same. The AI interface looks the same.
The difference only surfaces at scale, when analysts start encountering confident answers grounded in transcripts that got the entities, figures, or speaker attributions wrong.
This isn't a transcription problem. It's a platform integrity problem.
In a single-vendor world where expert network consolidation has collapsed three procurement conversations into one, transcript fidelity is the foundation of the entire stack. The consolidated AI layer is only as good as the clean, structured primary content it's grounded in. The firms that treat that content layer as critical infrastructure (and partner with transcription providers built specifically for their domain) are the ones positioned to win the consolidation cycle.
Everyone else is optimizing the wrong layer.
Expert Network Consolidation Demands a New Standard for Primary Content Quality
The structural shift isn't coming. It's here. Three procurement lines are collapsing into one platform buy, pricing is migrating from per-call to per-seat, and the AI search layer that every vendor ships is converging toward commodity status.
What remains as the durable differentiator is the thing closest to the source: the fidelity of the primary content feeding every downstream workflow.
That's the real lesson of expert network consolidation. The winners won't be the platforms with the flashiest AI demo. They'll be the ones whose content layer can withstand the compounding pressure of retrieval-augmented generation, entity extraction, and cross-document synthesis without introducing errors that cascade silently into investment decisions.
For the expert networks and financial data platforms building these consolidated stacks, the implication is concrete. Your transcription vendor ecosystem is now load-bearing infrastructure. Every misrecognized ticker, every garbled financial term, every speaker attribution error doesn't just degrade a single transcript.
It degrades the entire platform's analytical output.
The firms that recognize this early will build transcript quality into their evaluation frameworks, their vendor SLAs, and their content ingestion pipelines. The ones that don't will discover the problem downstream, when their clients start asking why the AI keeps hallucinating numbers that trace back to a transcription error on page four.
INFLXD works with expert networks and financial data platforms to measure, benchmark, and improve the accuracy of the transcripts powering their content libraries. If you're evaluating your transcription vendor stack (or preparing your platform for a consolidation cycle), start with visibility into what's actually in your transcripts today. Request a transcript quality audit from INFLXD and see exactly where your current vendors fall short on the financial terminology, named entities, and speaker accuracy that your AI layer depends on.
Powering institutional-grade transcription for expert networks.
INFLXD provides AI-powered, human-edited transcription with sub-1% error rates for the world's leading expert networks and financial research firms.
Visit inflxd.com →Keep reading.

Magnetar prepares AI-agent equity fund for 2026 launch
The $18 billion firm is building a long-biased equity strategy where hundreds of AI agents handle research work normally done by analyst teams.

Accenture Ventures takes stake in AlphaSense, sets agentic workflow partnership
The consulting firm's venture arm backs the market intelligence platform as the two move to embed AlphaSense data inside enterprise AI agents.

AlphaSense raises $350M at $7.5B valuation, crosses $600M ARR
The market intelligence platform extends its content moat and AI roadmap with fresh capital from J.P. Morgan Private Capital and Viking Global Investors.