Synthetic Experts in Expert Networks: Why Your Transcript Archive Is the Real Infrastructure
Synthetic experts in expert networks depend on transcript data quality, not archive size. Learn why entity accuracy and structure are the true Act III moat.
Synthetic Experts in Expert Networks: Why Your Transcript Archive Is the Real Infrastructure
You've got three vendor proposals on your desk, each promising an AI layer that can answer client questions directly from your transcript archive. The demos are sharp. The pitch decks are polished.
But here's the question nobody's slides address: what happens when the model confidently tells a buyside analyst that a company's gross margin expanded "twenty-five percentage points" because that's what your archive says, when the expert actually said "twenty-five basis points"?
That's the core tension facing synthetic experts in expert networks right now. Every major network is racing toward what we'd call Act III: AI systems trained on proprietary call archives that can surface expert-grade insight on demand, without scheduling a single call. The strategic conversation has shifted from "should we build AI?"
to "what do we build it on?" And the answer matters more than most boardrooms realize.
The model layer is commoditizing fast. Foundation models are available to everyone. The only durable differentiator is the proprietary corpus underneath.

But most of those corpora were captured by commodity transcription vendors optimized for speed and cost, not for the entity precision, speaker attribution, and structural fidelity that a synthetic expert demands. These archives were built for human readers who could infer context and correct errors on the fly. Machines don't do that.
They inherit every garbled ticker, every mis-attributed quote, every hallucinated figure, and they amplify those errors silently, at scale, with total confidence.
The prerequisite for Act III isn't a bigger archive or a better model. It's a cleaner, more structured, more verifiable dataset.
The networks that treat transcript data quality as foundational infrastructure will own this next era. Those that skip it will ship impressive demos built on unreliable ground. What follows is a detailed look at what "synthetic-expert grade" actually requires, where the quality gaps live, why they compound after deployment, and how to close them before your archive becomes a liability instead of a moat.
What Synthetic Experts Actually Are (and Why Expert Networks Are Building Them)
The term "synthetic expert" gets thrown around loosely. It's worth being precise about what it means, because the distinction between a synthetic expert and a search tool determines everything about the infrastructure required to build one.
From Expert Calls to On-Demand AI Personas
A synthetic expert isn't a transcript search bar with a chatbot skin. It's not a summarization layer that pulls snippets from your archive and stitches them together. A synthetic expert is an AI system trained on a network's proprietary transcript corpus that can reason about a new, specific question on demand, without scheduling a live call.
The difference is subtle but critical. A RAG-based search tool retrieves passages. A synthetic expert embodies reasoning patterns drawn from thousands of expert conversations, synthesizing perspectives across calls, industries, and time periods to produce an answer that mirrors the analytical depth of a real expert interaction.
It doesn't just find what someone said about semiconductor packaging costs in Q3 2024. It can reason about how those costs relate to broader supply chain dynamics across adjacent verticals, grounded in what dozens of experts have actually discussed.
That's the promise. And it's why the infrastructure underneath has to be radically better than what a keyword search requires.
The Three Acts of Expert Network Evolution
There's a useful framework for understanding where the industry sits right now.
**Act I was personalized scarcity. ** One-on-one expert calls, billed at $1,300 or more per hour, delivering deep insight but constrained by scheduling, availability, and cost. Every engagement was bespoke.
The value was high. The scalability was low.
**Act II was productized insights. ** Transcript libraries with near-zero marginal cost of replication. Tegus, Stream, and Third Bridge Forum validated this model.
A single expert call, once captured, could serve hundreds of clients. The unit economics shifted dramatically, but the format was still passive: read the transcript, draw your own conclusions.
**Act III is productized personalized insights. ** It combines the interactive depth of a live call with the scalability of a digital product. The synthetic expert answers your specific question, drawing on the full archive, in seconds.
No scheduling. No availability constraints. No $1,300-per-hour price tag per interaction.
Act III is where the industry is converging. The question isn't whether it'll happen. It's who builds it on a foundation that actually holds up.
Why the Expert Network Market Is Converging on Synthetic Expertise
The market dynamics make the direction unmistakable. The global expert network market reached roughly $3 billion in 2025, growing about 12% annually, with projections exceeding $4.86 billion by the end of 2026. That growth is attracting capital and accelerating the race toward AI-driven delivery.
The signals are already concrete. Qualitate raised $7 million in April 2026 to scale an AI-driven expert-intelligence platform built on over 350,000 minutes of expert discussions, with roughly 10,000 new minutes added weekly. Their own framing is telling: "the compounding data advantage is what separates a product from a platform."
AlphaSense integrates over 200,000 expert call transcripts covering more than 25,000 companies with an AI market-intelligence layer. Third Bridge is publishing guidance on AI tools for investment research.
Everyone's building the AI layer. That part isn't hard to see coming.
Here's what matters more: the model and orchestration layers are increasingly commoditized. AlphaSense built a proprietary LLM. Bloomberg trained BloombergGPT on financial text.
Foundation models are available to anyone with engineering talent and compute budget. The technology to build a synthetic expert is accessible. What's NOT accessible off the shelf is a proprietary, compliance-vetted, domain-specific corpus of real expert conversations.
That corpus is the asset. The synthetic expert is just the interface to it.
This is the strategic insight that separates networks building durable competitive advantage from those shipping impressive demos. The moat isn't the model. It's the data underneath.
And the quality of that data, its entity accuracy, its speaker attribution, its structural completeness, determines whether a synthetic expert produces reliable intelligence or confident-sounding noise.
The networks that already sit on massive transcript archives are in a genuinely strong position. They've spent years building something that can't be replicated overnight. But those archives were captured in an era when the transcription vendor ecosystem was optimized for human readability, not machine reasoning.
The gap between "we have the data" and "the data is synthetic-expert grade" is where the real work begins.
Why Proprietary Transcript Data Is the Moat, Not the Model
The previous section ended with a claim that deserves unpacking: the model isn't the moat. The data is. That's not a platitude.
It's a structural argument about where defensibility actually lives in the synthetic expert stack, and it has direct implications for how expert networks should allocate capital right now.
The AI Parity Problem: Generic Models on Public Data Produce Generic Outputs
Here's the core issue with treating the model layer as the differentiator. Foundation models are converging. The gap between the best proprietary LLM and the second-best narrows with every release cycle.
Engineering talent is mobile. Compute is purchasable. Orchestration frameworks are open source.
InsightAgent put it cleanly: "AI is only as useful as the dataset it is grounded in. Generic models trained on public information tend to produce generic outputs. Tools built on proprietary datasets can surface insights that are not already priced into the market."
That framing matters. A synthetic expert built on publicly available earnings calls, SEC filings, and news articles is just a chatbot with a brand name. Every competitor has access to the same inputs.
The outputs converge toward the same consensus view. There's no alpha in consensus.
The alpha lives in proprietary conversations that no competitor possesses. The unpublished perspective of a former VP of supply chain at a mid-cap industrial. The candid assessment of regulatory risk from a retired FDA reviewer.
Those conversations exist in expert network archives and nowhere else. That's the asset.
Proprietary Expert Call Archives as Defensible Data Assets
Expert networks have spent years (in some cases, over a decade) building transcript archives that can't be replicated overnight. AlphaSense integrates over 200,000 expert call transcripts covering more than 25,000 companies. Qualitate operates a library of over 350,000 minutes of expert discussions, adding roughly 10,000 new minutes weekly.
These are massive, proprietary corpora with genuine competitive value.
But volume alone doesn't create a moat. It creates a prerequisite.
A polluted archive that compounds errors is a liability that grows in the wrong direction. If 8% of entity mentions are wrong across 200,000 transcripts, that's not a rounding error. It's a systematic source of false premises baked into every embedding, every retrieval index, every reasoning chain the synthetic expert builds.
The archive's value isn't measured in transcript count. It's measured in the fidelity of what those transcripts actually contain.
This is where the historical capture problem surfaces. These archives were built when the primary use case was a human analyst skimming a document. A human can infer that "air is capital" probably means "Ares Capital."
A machine can't. The commodity transcription vendors that processed these calls were never designed to produce data at the precision a synthetic expert requires. That's not a failure of the networks that commissioned the work.
It's a limitation of the vendor ecosystem that existed at the time.
Supply, Compliance, and Corpus Quality: The Three-Layer Moat for Expert Networks
So what actually constitutes a defensible position in the synthetic expert era? InsightAgent's framing is instructive: "The real moat is supply and compliance. The expert relationships, the trust, the compliance infrastructure are hard to replicate.
Orchestration and intelligence, by contrast, are increasingly available as technology."
That's two layers. We'd argue there are three:
- Supply. The expert relationships, the recruiter networks, the ability to source a niche specialist in 48 hours. This is hard-won and deeply defensible.
- Compliance. The legal infrastructure, the consent frameworks, the audit trails that make every conversation usable in a regulated context. You can't shortcut this.
- Corpus quality. The entity accuracy, speaker attribution, and structural completeness of the archive itself. This is the layer that determines whether supply and compliance translate into a functioning synthetic expert or a confident-sounding liability.
The first two layers are strengths that established expert networks already possess. They're the product of years of operational investment and institutional trust. The third layer is where the gap exists, and it's a gap created by transcription vendors that lacked the domain models to serve financial conversations at the accuracy level synthetic experts demand.
The model layer commoditizes. The proprietary, compliance-vetted, high-fidelity corpus does not. Networks that recognize this distinction will invest accordingly, treating transcript quality not as a back-office cost center but as the infrastructure that makes their AI strategy defensible.
The next section gets specific about what "synthetic-expert grade" quality actually requires at the transcript level, and why the bar is meaningfully higher than what most transcription vendors have historically delivered.
Transcript Data Quality: What 'Synthetic-Expert Grade' Actually Requires
The previous section established that the moat is the corpus, not the model. But calling it a "moat" assumes the corpus is actually usable as synthetic expert infrastructure. That's a big assumption.
Most transcript archives were captured for human consumption, and the quality bar for a human reader is fundamentally different from the bar for an AI system that needs to reason from the data.
So what does "synthetic-expert grade" actually mean at the transcript level? It breaks down into four pillars, each with concrete implications for how expert networks should evaluate the fidelity of their archives.
Entity Accuracy: Tickers, Figures, and Domain Terminology
This is the most visible failure mode, and the one with the sharpest downstream consequences. When an expert says "twenty-five basis points," a synthetic expert that learned "twenty-five percentage points" from a mis-transcribed archive will reason from a false premise and present it with total confidence. The error isn't flagged.
It's inherited.
Entity accuracy covers tickers, company names, named individuals, drug compounds, financial metrics, and numerical figures. It's the layer where commodity transcription vendors consistently fall short because generic ASR models lack the domain vocabulary to handle financial and technical terminology at the precision synthetic experts demand.
Consider what happens when an expert discusses "EBITDA margin compression in the mid-cap specialty chemicals segment." A generic ASR model might transcribe "EBITDA" correctly (it's common enough) but mangle "specialty chemicals" into something phonetically similar and semantically wrong. The human reader catches it instantly.
The embedding model doesn't. It encodes the error as fact, and every retrieval query that touches that segment of the archive now returns contaminated results.
Entity accuracy isn't a nice-to-have. It's the foundation that every other quality pillar depends on.
Speaker Attribution and Diarization Accuracy for Expert Call Archives
A forward-looking estimate from a former CFO carries fundamentally different weight than the same words from a junior analyst asking a question. If your archive can't reliably distinguish who said what, a synthetic expert can't weight perspectives appropriately. Mis-attribution doesn't add noise.
It invalidates the analytical value of the data.
This is where diarization accuracy becomes critical. AI diarization tools often falter in conversations with many participants, similar-sounding voices, or frequent interruptions. Expert calls frequently involve all three.
The result is speaker labels that drift mid-conversation, attributing a bullish supply-chain outlook to the interviewer instead of the 20-year industry veteran.
For a human skimming the transcript, context clues make the real speaker obvious. For a model learning reasoning patterns across thousands of calls, there are no context clues. There's only the label.
Wrong label, wrong lesson.
Structural Completeness: Turning Raw Text Into Machine-Consumable Data
Raw text isn't a dataset. It's a wall of words. A synthetic expert can't learn reasoning patterns from an undifferentiated block of prose any more than a quant can build a model from an unsorted spreadsheet.
Structural completeness means the transcript includes:
- Speaker labels tied to verified identities and roles
- Timestamps enabling temporal alignment with other data sources
- Q&A segmentation distinguishing questions from answers, hypotheses from conclusions
- Entity tagging marking tickers, companies, metrics, and figures as typed, queryable objects
Without this structure, a synthetic expert can't distinguish a direct observation from secondhand speculation. It can't tell whether a statement was a confident assertion or a tentative response to a leading question. It treats everything as equivalent signal, which means it treats noise as signal too.
The transcript libraries built during Act II are valuable assets. But they were captured by transcription vendors whose output format was optimized for readability, not for machine consumption. Turning those archives into structured, queryable corpora is a prerequisite for any serious synthetic expert deployment.
Verifiability and Confidence Metadata for AI-Grounded Claims
The first three pillars ensure the synthetic expert reasons correctly. The fourth ensures its claims are auditable.
Verifiability means every assertion a synthetic expert makes can be traced back to a specific source transcript, a specific speaker, a specific moment in a specific call. Confidence metadata (indicating which spans were machine-transcribed with high certainty versus flagged for human review) creates the provenance trail that makes this possible.
This isn't about regulatory compliance, though that matters too. It's about market dynamics. Users will naturally gravitate toward platforms that ground every assertion with a direct citation back to a source transcript.
A synthetic expert that says "a former VP of procurement at [Company X] described lead times extending from 6 weeks to 14 weeks in Q2 2025" and links to the exact passage is categorically more valuable than one that says "lead times are extending" with no source.
The platforms that build this citation infrastructure into their synthetic expert layer won't just earn user trust. They'll define what "trustworthy" means in this category, and every competitor without it will look like guesswork by comparison.
These four pillars (entity accuracy, speaker attribution, structural completeness, and verifiability) collectively define what it means for transcript data quality to be synthetic-expert grade. The bar is meaningfully higher than what the commodity transcription vendor ecosystem has historically delivered. That gap is where the next section picks up.
How Commodity Transcription Vendors Created the Expert Network Data Quality Gap
The previous section laid out four pillars of synthetic-expert-grade transcript quality. The natural follow-up: if the bar is that clear, why don't most archives meet it?
The answer isn't complicated, and it has nothing to do with the networks themselves. Expert networks made rational decisions based on the tools available at the time. When these archives were built, the primary consumer was a human analyst who could mentally correct a garbled ticker or infer the right speaker from context.
The transcription vendor ecosystem optimized accordingly: fast turnaround, low cost per minute, readable output. Nobody was building for a downstream machine-consumption use case that didn't yet exist.
That's not a strategic failure. It's a timing problem. The vendor ecosystem built for Act II.
Act III demands something fundamentally different.
Why Generic ASR Models Fail on Specialized Expert Call Audio
Most commodity transcription vendors run generic automatic speech recognition models trained on broad conversational English. These models perform well on everyday vocabulary. They weren't built for pharmaceutical development pipelines, energy trading terminology, or semiconductor supply chain dynamics.
The gap is structural, not incremental. A generic ASR model doesn't have "EBITDA" in its vocabulary by accident. It picked it up because the term appears frequently enough in general financial media.
But "adalimumab biosimilar pricing," "Henry Hub basis differential," or "advanced packaging substrate capacity"? These are domain-specific phrases that generic models either mangle phonetically or replace with higher-probability common words. The output looks clean.
It reads fluently. And it's wrong in exactly the places that matter most.
Expert networks process thousands of calls monthly across dozens of specialized verticals. The transcription vendors serving those calls typically deploy a single ASR model across all of them. There's no domain adaptation, no custom vocabulary layer, no vertical-specific language model.
The same engine that transcribes a call about consumer retail transcribes a call about rare-earth mineral supply chains. The error patterns are predictable, and they cluster precisely around the high-value terminology that makes expert calls worth capturing in the first place.
The Three Failure Points in Expert Network Transcription Pipelines
The quality gap doesn't originate at a single point. It compounds across three stages of the transcription pipeline, each one degrading the output further.
Real-time capture is where it starts. Generic ASR models process the audio stream as it arrives, making word-level predictions based on acoustic probability. Without domain-specific language models or custom dictionaries, the system defaults to the most statistically likely word in general English.
"Ares Capital" becomes "air is capital." "Basis points" becomes "percentage points." These aren't random errors.
They're systematic substitutions driven by a model that lacks the vocabulary to make the right call.
Post-call processing is where the gap should narrow but typically doesn't. Most commodity vendors use a single-pass ASR approach optimized for speed and cost. There's no second-pass review with a domain-tuned model.
No custom dictionary lookup against known entities in the expert's industry. No human review layer for low-confidence spans. The transcript that comes out of real-time capture is, in most cases, the final deliverable.
Whatever errors the first pass introduced are now permanent.
Downstream integration is the third and least visible failure point. A transcript that's 95% accurate at the word level may sound acceptable. But if it lacks reliable speaker identification, timestamp alignment, topic segmentation, or entity tagging, it's functionally incomplete for machine consumption.
The words might be mostly right. The structure that makes those words queryable, attributable, and verifiable simply isn't there. This isn't a quality control gap.
It's a format gap. The output was designed to be read, not parsed.
The compounding effect across these three stages is what creates the real problem. Degradation at the capture layer feeds into an unverified post-processing step, which produces an unstructured final output. The analyst (or now, the AI model) reviewing that output is working with data that's been degraded at every stage of production, with no visibility into where or how the degradation occurred.
There's no confidence score on individual spans. No flag marking which entities were low-certainty. No metadata distinguishing verified passages from best-guess approximations.
This is a structural limitation of commodity transcription tooling that was never designed for the use case expert networks now need it to serve. The vendors built what the market asked for: fast, cheap, readable transcripts. The market's requirements have changed.
The vendor ecosystem, largely, hasn't.
That mismatch is what makes the amplification problem (covered in the next section) so dangerous. When a synthetic expert trains on an archive shaped by these three failure points, it doesn't just inherit the errors. It compounds them in ways that are far harder to detect and far more expensive to fix after the fact.
The Amplification Problem: Why Fixing Transcript Data Quality After AI Deployment Fails
The previous section traced how commodity transcription vendors degrade expert call archives across three pipeline stages. That degradation is already a problem for human analysts. For a synthetic expert, it's something worse: a self-reinforcing error engine.
Here's the critical distinction. A human analyst who encounters a garbled entity in a transcript can pause, cross-reference, and correct. A synthetic expert can't.
It doesn't encounter errors. It absorbs them. It learns from them, reasons on top of them, and presents conclusions derived from false premises with full confidence and zero caveat.
The error isn't repeated. It's laundered through layers of abstraction until it's invisible.

That's the amplification problem. And it's why treating transcript data quality as something you can fix after the AI layer is in production isn't just optimistic. It's structurally unworkable.
How Noisy Transcripts Compound Errors Through Embeddings, Retrieval, and Tuning
Think about what actually happens when a synthetic expert is built on top of a transcript archive. The process isn't a single step. It's a chain, and each link in that chain encodes the quality (or the noise) of the data beneath it.
**Embeddings come first. ** Every transcript gets converted into vector representations that capture semantic meaning. If a transcript says "percentage points" where the expert said "basis points," the embedding doesn't flag the discrepancy.
It encodes the wrong information as ground truth. That corrupted vector now sits in the retrieval index alongside thousands of others, indistinguishable from accurate ones.
**Retrieval is the second link. ** When a user asks the synthetic expert about margin dynamics in a specific sector, the retrieval layer pulls the most semantically relevant passages from the archive. It has no mechanism to distinguish between a passage that's accurate and one that's been mis-transcribed.
A noisy transcript that happens to be topically relevant gets surfaced with the same confidence as a clean one. The retrieval system is doing exactly what it's designed to do. It just can't evaluate what it's retrieving.
**Tuning and reasoning sit at the top of the chain. ** If the synthetic expert is fine-tuned on the corpus (or even if it's using in-context learning from retrieved passages), it's building its reasoning patterns on whatever the data contains. A model that repeatedly sees incorrect entity relationships across hundreds of transcripts doesn't treat them as anomalies.
It treats them as patterns. It generalizes from them.
The result is an error that's been transformed three times: from a transcription mistake, to a corrupted embedding, to a retrieval signal, to a learned reasoning pattern. By the time it surfaces in a synthetic expert's response, there's no trace of the original mis-transcription. The answer looks authoritative.
It cites the archive. And it's wrong.
The True Cost of Retroactive Data Remediation in Expert Network AI Infrastructure
Some teams assume they can ship the AI layer now and clean up the transcripts later. The logic sounds reasonable: get the product to market, then improve the data incrementally. In practice, this creates a remediation cost structure that scales in exactly the wrong direction.
Every embedding built from a noisy transcript has to be rebuilt when the underlying transcription is corrected. Every retrieval evaluation that was benchmarked against a noisy ground truth has to be redone, because the evaluation metrics themselves were measuring performance against bad data. Every downstream model tuned on the noisy corpus has to be re-tuned.
This isn't a patch. It's a rebuild of the entire data layer while the production system is live.
And the cost grows with every call added to the archive.
Consider what this means for a network adding thousands of new expert calls monthly. If those calls are still being processed by commodity transcription vendors with the same generic ASR limitations, every new transcript deposited into the archive increases the eventual remediation burden. The corpus isn't compounding in value.
It's compounding in technical debt. Six months of noisy capture on top of an already-noisy archive doesn't create a six-month remediation project. It creates a problem that's geometrically harder to unwind because the embeddings, retrieval indices, and model weights have all been shaped by the accumulated noise.
The asymmetry is stark. Networks that fix data quality at the capture layer (before any AI system touches the data) avoid this entire cost structure. Those that defer it face a growing liability that scales with every call recorded, every embedding generated, every retrieval index rebuilt on contaminated vectors.
This is why transcript data quality for expert networks isn't an optimization to pursue after the synthetic expert ships. It's a prerequisite that determines whether the synthetic expert is buildable at all on a foundation that holds. You can't bolt fidelity onto an archive retroactively without effectively starting over on the data infrastructure layer.
The networks that recognize this now will build their AI strategy on solid ground. The ones that don't will eventually arrive at the same conclusion, just at significantly higher cost.
Building Expert Network AI Infrastructure: From Archive to Synthetic-Expert-Grade Corpus
The previous section made the case that fixing transcript quality after deployment is structurally unworkable. The cost compounds in the wrong direction, and the technical debt scales with every call added to a noisy archive. So what does the workable path actually look like?
It starts with a shift in framing. The transcript libraries that expert networks have built over years of Act II operations are genuinely valuable assets. They represent proprietary conversations that can't be replicated.
The gap isn't in the archive's existence or its strategic value. It's in how commodity transcription vendors historically captured those conversations, using generic ASR models that weren't designed for the domain precision that synthetic expert applications demand.
Closing that gap is a tractable engineering and process problem. Not a moonshot. It requires three interlocking capabilities.
Domain-Tuned Capture: Accurate Entities and Reliable Diarization at the Source
The single highest-leverage intervention is getting the transcription right the first time. That means replacing generic ASR with models trained on the specific vocabulary of expert calls: financial terminology, pharmaceutical compounds, industrial process language, sector-specific acronyms.
Domain-tuned capture isn't just "better ASR." It's a fundamentally different approach to how the audio-to-text pipeline works. Custom dictionaries populated with client-specific entity lists (tickers, company names, key personnel, product names) give the model prior knowledge about what it's likely to hear.
When an expert says "Ares Capital," a domain-tuned model with that entity in its vocabulary doesn't default to the phonetically similar "air is capital." It resolves correctly because it knows the term exists.
Speaker separation benefits from the same principle. Multi-track recording, where each participant's audio is captured on a separate channel, gives the diarization system clean input rather than forcing it to untangle overlapping voices from a single mixed stream. The result is speaker attribution that's reliable from the start, not a best-guess approximation that drifts mid-conversation.
This is where the constraint has always been. The commodity vendor ecosystem offered one generic model for every vertical, every call type, every domain. Expert networks deserved better tooling.
Now it exists.
Structured Output: Typed Entities, Q&A Segmentation, and Machine-Consumable Formats
Accurate words aren't enough. A synthetic expert doesn't consume a transcript the way a human analyst does. It needs structure.
That means the transcript is delivered not as a block of text but as a typed, queryable dataset. Speaker labels carry verified identities, roles, and affiliations. Timestamps align to every speaker turn, enabling temporal correlation with market data and other sources.
Q&A segmentation distinguishes questions from answers, so the model can differentiate a hypothesis posed by an interviewer from a conviction expressed by a 20-year industry veteran.
Entity tagging is where structure becomes especially powerful. Companies, people, products, metrics, and figures are marked as typed objects, not just strings of text. "EBITDA" isn't a word in a sentence.
It's a tagged financial metric linked to a specific company context and a specific speaker. This is what transforms a readable document into training data that a synthetic expert can learn reasoning patterns from.
Without this structural layer, even a perfectly accurate transcript is still just prose. With it, the archive becomes a machine-consumable corpus that compounds in value with every call added.
Human Review on Confidence-Flagged Spans: The Hybrid Accuracy Model
Pure automation can't deliver synthetic-expert-grade fidelity across every span of every call. Neither can pure human transcription, which is too slow and too expensive to scale across the thousands of calls expert networks process monthly.
The workable model is hybrid. AI handles the high-confidence majority of the transcript. Human domain experts review only the spans where the model's confidence drops below a defined threshold.
These are the exact moments that matter most: unfamiliar entity names, ambiguous numerical references, overlapping speech segments where diarization certainty is low.
This isn't "human transcription." It's targeted human intervention governed by confidence metadata. The AI system knows what it doesn't know, and it routes those specific passages to reviewers with the domain expertise to resolve them correctly.
The result is auditable accuracy at scale, with a clear provenance trail showing which spans were machine-confirmed and which were human-verified.
That confidence metadata also flows downstream. When a synthetic expert surfaces a claim grounded in a passage that was human-reviewed and verified, the citation carries a different weight than one grounded in a machine-only span. This is how verifiability gets built into the infrastructure layer, not bolted on after the fact.
The Path from Act II Archive to Act III Asset
These three capabilities (domain-tuned capture, structured output, and hybrid human review) aren't independent features. They're an integrated pipeline that turns the expert call archives of Act II into the AI infrastructure of Act III.
The transcript libraries already exist. They're large, proprietary, and strategically valuable. The gap between their current state and synthetic-expert-grade fidelity was created by a vendor ecosystem that optimized for speed and cost over domain precision.
That gap is closable. It requires treating the transcription layer as core infrastructure rather than a commodity input, and investing in capture quality with the same seriousness that expert networks have always invested in expert supply and compliance.
The networks that close this gap will own the compounding advantage that Qualitate described: "the compounding data advantage is what separates a product from a platform." But compounding only works on a clean foundation. Every accurately captured, properly structured, human-verified transcript deposited into the archive increases the synthetic expert's value.
Every noisy one increases its liability.
The choice isn't whether to build. It's whether to build on data you can trust.
Auditing Your Expert Call Archive: A Practical Framework for Data Fidelity Assessment
The previous section outlined how to build the pipeline going forward. But what about the archive that already exists? Before any synthetic expert deployment, you need a clear-eyed assessment of what your corpus actually contains.
Not what it should contain. Not what the transcription vendor promised. What's actually in the files.
This is the "what to do Monday morning" section. Here's a framework your data team can execute immediately.
Sampling Methodology for Transcript Accuracy Measurement
The first step is pulling a sample that's statistically meaningful and structurally representative. Don't cherry-pick your cleanest calls. Don't limit the sample to a single vertical or a single transcription vendor.
Pull transcripts across different industries (healthcare, industrials, technology, financials), different call formats (one-on-one, multi-participant panels, moderated roundtables), and different time periods. If you've used multiple transcription vendors over the years, sample from each. The goal is to surface systematic quality patterns, not to confirm that your best calls look good.
A sample of 100 to 200 transcripts, stratified across these dimensions, gives you enough coverage to identify vendor-level and format-level trends. For each transcript in the sample, you'll need access to the original source audio. Without it, there's nothing to measure against.
Key Metrics: Entity-Level Accuracy, Diarization Accuracy, and Structural Completeness
Three metrics define archive readiness for synthetic expert applications. Word error rate alone won't tell you what you need to know.
Entity-level accuracy is the metric that matters most. Compare every transcribed entity (company names, tickers, people, financial figures, domain-specific terms) against the source audio. Calculate the entity error rate as a percentage of total entity mentions.
This is distinct from word error rate, and the distinction is critical. A transcript can score 97% at the word level and still carry a 15% entity error rate if the errors cluster in the high-value terms. Those are exactly the terms a synthetic expert will reason from.
Diarization accuracy measures whether speaker labels are correctly attributed. Listen to a representative set of speaker turns in each sampled transcript and verify them against the audio. Calculate the percentage of turns correctly assigned.
Flag systematic failure patterns: does diarization break down consistently when more than three speakers are present? When speakers have similar vocal characteristics? When there's crosstalk?
These patterns tell you whether the problem is isolated or structural.
Structural completeness assesses whether each transcript includes the metadata that makes it machine-consumable. Score each transcript against a rubric:
- Are speaker labels present and consistent throughout?
- Are timestamps included at the turn level?
- Is Q&A segmentation marked (questions distinguished from answers)?
- Are entities tagged as typed objects, or do they exist only as unstructured text?
Each dimension gets a binary or graded score. Aggregate across the sample to quantify the gap between "we have the data" and "the data is synthetic-expert grade."
What the Audit Tells You
The output of this framework isn't a pass/fail grade. It's a map.
It tells you which vendors produced the highest entity error rates. It tells you which call formats break diarization. It tells you whether your archive has the structural metadata that a synthetic expert requires, or whether it's a collection of readable prose that a machine can't parse into attributable, queryable data.
Most importantly, it tells you whether your corpus is an asset ready to compound or a liability that needs remediation before you build on it. That's the question every expert network needs answered before writing the first line of synthetic expert code. The networks that audit first will build on solid ground.
The ones that skip this step will discover the same problems later, after they've been amplified through embeddings, retrieval indices, and model weights, at a cost that's orders of magnitude higher.
The audit is cheap. The alternative isn't.
The Durable Moat for Expert Networks: Clean Data, Not Bigger Archives
The model layer will commoditize. The orchestration layer will commoditize. The retrieval frameworks, the fine-tuning pipelines, the chat interfaces: all of it will converge toward parity.
What won't commoditize is a proprietary, compliance-vetted, entity-accurate, attribution-reliable, structured, and verifiable corpus of real expert conversations. That's the asset that compounds. Everything else is infrastructure you rent.
Why Transcript Archive Fidelity Decides the Winners of Act III
The expert network industry is converging on synthetic experts as the next product surface. That much is clear from the capital flows, the product roadmaps, and the competitive positioning across the market. Qualitate's framing captures it precisely: "the compounding data advantage is what separates a product from a platform."
But compounding works in both directions.
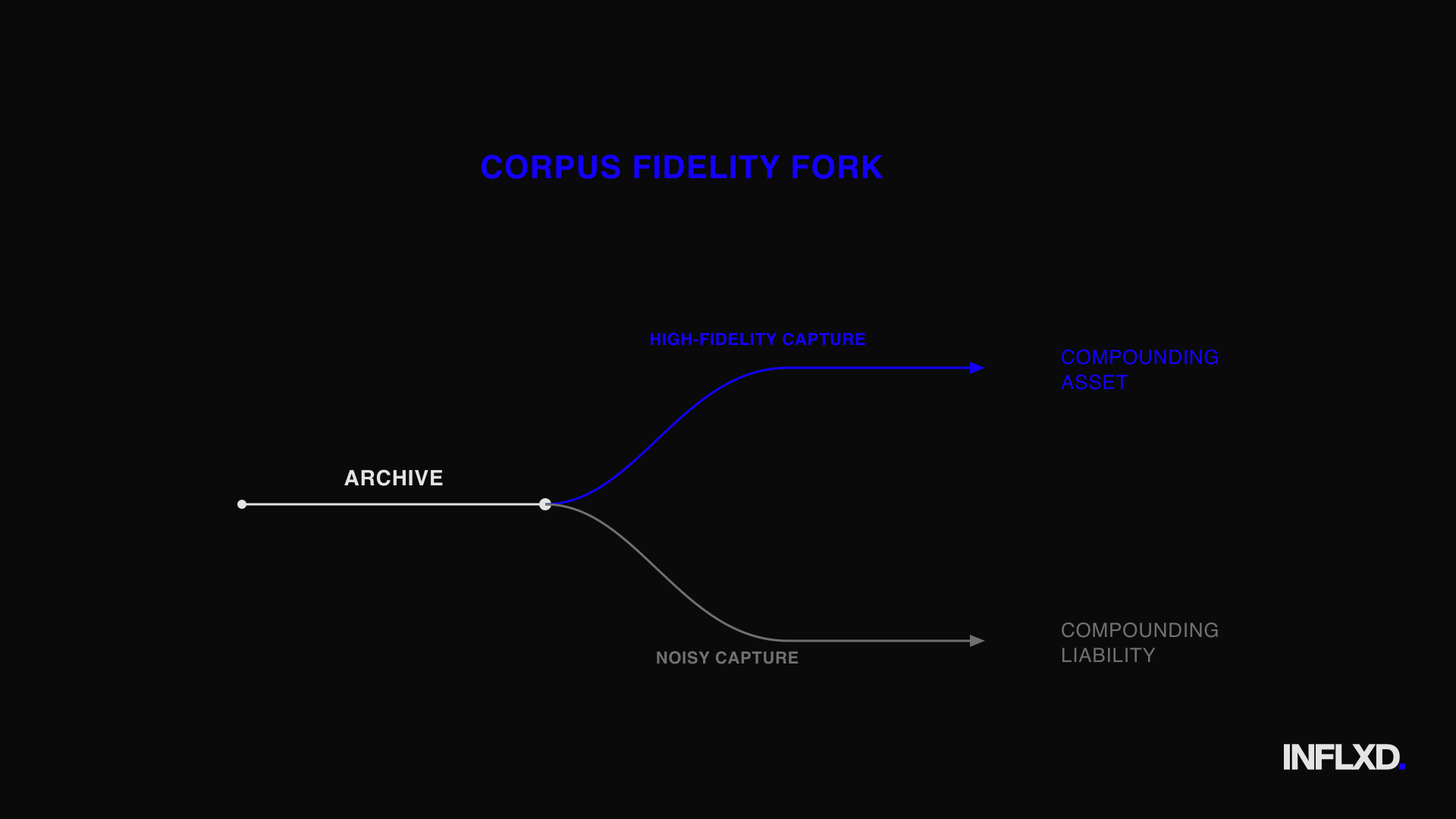
An archive captured at high fidelity compounds into a synthetic expert that gets more reliable, more nuanced, and more defensible with every call added. An archive riddled with entity errors, drifting speaker labels, and missing structure compounds into technical debt that grows more expensive to remediate with every quarter that passes. The networks that invest in corpus fidelity now are building an asset whose value accelerates.
Those that defer are accumulating a liability whose cost accelerates just as fast.
The winners of Act III won't be determined by who has the biggest archive or the most sophisticated model. They'll be determined by who built on data they could trust.
Treating the Proprietary Corpus as the Single Durable Asset
Here's what expert networks already have that can't be replicated overnight: the expert relationships, the compliance infrastructure, the years of accumulated conversations across thousands of specialized verticals. These are genuinely hard-won advantages. The gap isn't strategic.
It's narrow and specific: the fidelity of the capture layer.
That gap was created by a commodity transcription vendor ecosystem that optimized for speed and cost in an era when human readability was the only requirement. It's a solvable problem. And closing it is the highest-leverage investment an expert network can make before the synthetic expert era fully arrives.
It's already arriving.
INFLXD exists to close exactly this gap. Not as another commodity vendor, but as a domain-tuned capture and structuring partner that stands alongside expert networks to ensure their archives compound in the right direction. The archive is the asset.
The question is whether it's being treated like one.
Why Synthetic Expert Infrastructure Starts with Transcript Quality
Every expert network sitting on a decade of proprietary call transcripts is sitting on something genuinely rare. Not because of volume. Because those conversations contain primary insights that no public dataset, no SEC filing, no earnings call transcript can replicate.
But rarity isn't the same as readiness.
The synthetic expert layer will reward networks whose archives are entity-accurate, attribution-reliable, and structurally consistent. It'll punish those whose archives were captured by commodity transcription vendors optimizing for speed and cost rather than domain fidelity. The model doesn't know the difference between a real company name and a hallucinated one.
It trusts whatever's in the corpus. That's the core risk, and it's also the core opportunity.
The firms that treat transcript quality as infrastructure (not a back-office line item) will build the moat that actually holds. Not because they chose the best LLM or the slickest orchestration framework. Those layers are converging fast.
The durable advantage is a clean, structured, verifiable proprietary corpus that no competitor can replicate and no foundation model can substitute.
Fixing this after the AI layer ships isn't just harder. It's an order of magnitude more expensive: re-transcription, re-embedding, re-validation, re-tuning. Every month of delay adds volume to the remediation backlog.
The right time to fix it is before the first retrieval query hits production.
INFLXD works with expert networks and financial data platforms to benchmark transcript accuracy across their vendor pipelines, identifying exactly where entity errors, attribution failures, and domain-specific gaps are degrading archive quality. If you're evaluating synthetic expert infrastructure, start with the layer everything else depends on. Run your transcripts through INFLXD's quality benchmarking process and see precisely where your current vendors are falling short.
Powering institutional-grade transcription for expert networks.
INFLXD provides AI-powered, human-edited transcription with sub-1% error rates for the world's leading expert networks and financial research firms.
Visit inflxd.com →Keep reading.

Magnetar prepares AI-agent equity fund for 2026 launch
The $18 billion firm is building a long-biased equity strategy where hundreds of AI agents handle research work normally done by analyst teams.

Accenture Ventures takes stake in AlphaSense, sets agentic workflow partnership
The consulting firm's venture arm backs the market intelligence platform as the two move to embed AlphaSense data inside enterprise AI agents.

AlphaSense raises $350M at $7.5B valuation, crosses $600M ARR
The market intelligence platform extends its content moat and AI roadmap with fresh capital from J.P. Morgan Private Capital and Viking Global Investors.